Index
DBMS를 다루는데 있어서 데이터의 조회를 빠르게 하기위해선 Index가 필수적이라고 할만큼 중요한 요소입니다. Index에는 Clustered Index와 Non-Clustered Index가 있는데 이들의 차이는 아주 간단한 차이를 갖고 있습니다. 처음부터 이해하기에는 어려울 수 있지만 실행계획을 차근차근 보면서 이해하다 보면 Index에 대해 심도있게 알아갈 수 있습니다.
Index
사전적 정의로 목차, 색인과 같은 뜻을 갖고 있습니다. 흔히 책에서 원하는 챕터나 단어를 찾을 때 책의 맨 앞장이나 맨 뒷장을 보게 됩니다. 가령 110페이지에 원하는 정보가 있을 경우 페이지 번호를 보고 바로 110페이지를 찾아서 보게 됩니다. DB 이런 역할을 도와주는 기능이 Index입니다. 원하는 것을 빠르게 찾아주는 역할을 합니다. 좀 더 자세한 인덱스 개념은 아래 URL을 참고 바랍니다
\- Index의 원리 : http://wiki.gurubee.net/pages/viewpage.action?pageId=27428394
-
Clustered Index
- 테이블내에서 단 한개만 존재할 수 있습니다
- 테이블 조회시
Clustered Index에 의해 정렬됩니다 - 주로
Primary Key로 쓰이며 키값과 페이지 번호로 데이터를 찾아냅니다 - 테이블에 데이터가 삽입되는 순서에 상관없이
Clustered Index로 생성되어 있는 컬럼을 기준으로 정렬합니다 Non Clustered Index로 지정하지 않은 컬럼으로 조회 하거나Clustered Index의 키값으로 조회시 Full-Scan하여 조회합니다
-
Non Clustered Index
- 테이블내에서 여러개 존재할 수 있습니다
- 테이블의 DML(UPDATE, INSERT, DELETE)가 빈번하게 일어날 경우 성능저하가 일어날 수 있습니다
Non Clustered Index가 걸려있더라도 데이터가 적거나 DB의 자체적 성능 판단 하에Clustered Index로 조회하기도 합니다- 테이블을 Full-Scan하지않고 원하는 데이터만 찾아서 조회합니다
MSSQL(SQL SERVER) Index Example
MSSQL에서 제공하는 실행계획을 이용하여 Index에 대해 예제로 살펴보겠습니다.
-- 중복 허용 Index
CREATE INDEX [인덱스명] ON [테이블명] ([컬럼명] [정렬기준])
-- Example
CREATE INDEX IDX_SEQ_NO ON DBO.TMP_TABLE(NAME ASC)
-- 중복 비허용 Index(성능이 더 우수)
CREATE UNIQUE INDEX [인덱스명] ON [테이블명] ([컬럼명] [정렬기준])
-- Example
CREATE UNIQUE INDEX IDX_SEQ_NO ON DBO.TMP_TABLE(NAME DESC)
-
(MSSQL)Clustered Index
- 먼저 샘플 테이블을 생성해 줍니다.
seq_no컬럼에primary key를 선언함으로써seq_no컬럼이Clustered Index역할을 하는 컬럼이 되었습니다.
CREATE TABLE DBO.PRIMARYKEY_TABLE( SEQ_NO BIGINT NOT NULL PRIMARY KEY , NAME VARCHAR(10) NULL , YEAR NVARCHAR(10) NULL ) BEGIN DECLARE @NUM INT = 1; WHILE (@NUM < 50000) BEGIN INSERT INTO DBO.PRIMARYKEY_TABLE VALUES(@NUM, 'Name' + CAST(@NUM AS VARCHAR(10)), CAST(@NUM AS VARCHAR(10)) + '살') SET @NUM = @NUM + 1; END END- 아래그림을 참고하면
YEAR컬럼이6살인 데이터를 하나 조회하는데 테이블을 풀스캔하여 모든행을 읽어들였습니다 Non Clustered Index가 설정되어 있지않은 컬럼의 데이터를 조회할 때는, 테이블의 데이터를 순차적으로 읽어서 원하는 데이터를 찾더라도 테이블의 끝까지 찾기때문에 테이블 Full-Scan이 일어납니다- 테이블 조회시 seq_no를
Primary Key로 잡았기 때문에Clustered Index가 되었으며, seq_no에 의해 정렬이 일어납니다 Clustered Index에 의한 조회가 일어났으므로 실행계획에Clustered Index(Clustered)라고 나타납니다
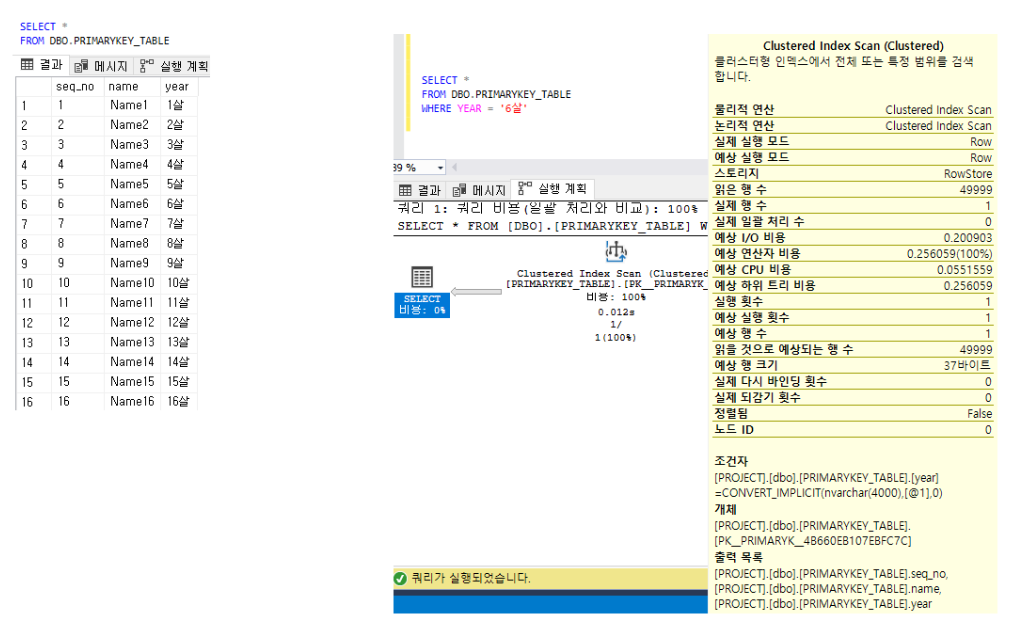
-
(MSSQL)Non Clustered Index
- 위에서 생성한 테이블에 Index를 생성해 줍니다
NAME컬럼에IDX_NAME로 Index를 생성함으로써NAME컬럼이Non Clustered Index역할을 하는 컬럼이 되었습니다.- 실제로 읽은 행은
WHERE조건을 만족하는 행을 읽었으며 테이블을 Full-Scan하지 않고 1개의 행만 읽었습니다 Non Clustered Index에 의한 조회가 일어났으므로 실행계획에Index Seek(NonClustered)이라고 나타납니다
CREATE INDEX IDX_NAME ON DBO.PRIMARYKEY_TABLE(NAME)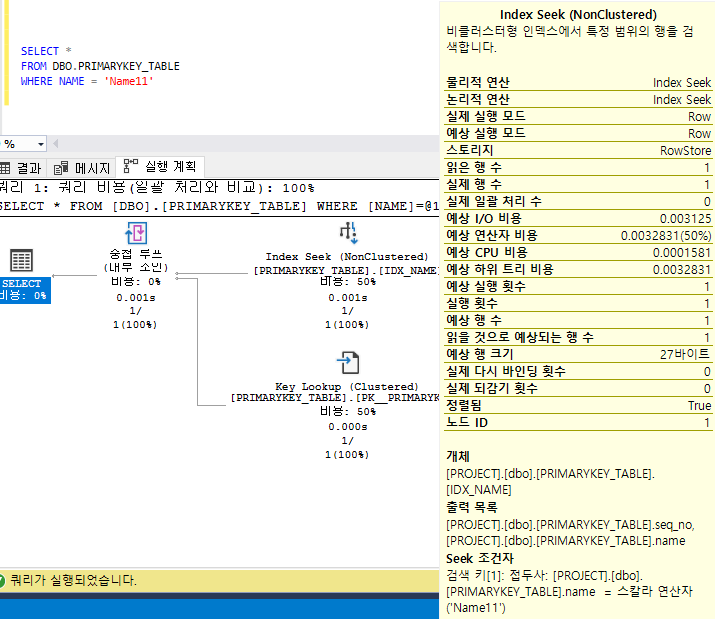
-
(MSSQL)Clustered / Non Clustered Index 성능 차이
- 아래의
Clustered Index와Non Clustered Index의 성능차이를 보면 확연한 차이를 느낄 수 있습니다 Clustered Index를 이용하여 1개의 데이터를 찾으려고 할때 드는 연산자 비용, CPU비용, 하위 트리 비용이 월등히 큽니다- 찾으려고 한 실제 행수는 1개인데
Clustered Index에서는 Full-Scan하여 5만개의 행(읽은 행수 + 실제 행수)을 모두 읽었고,Non Clustered Index에서는 1개의 행만 읽었습니다 - 많은 데이터를 찾으려고 할때는 Full-Scan이 낫지만 적은데이트를 찾으려고 할때는
Non Clustered Index를 이용하여 원하는 데이터만 찾는 것이 성능상으로도 유리합니다

- 아래의
-
(MSSQL)Key Lookup / RID Lookup
- MSSQL에서 인덱스 실행계획을 보면 인덱스 걸린 컬럼을 이용하여 탐색할 때 인덱스가 찾고자하는 행의 탐색방법이 나오는데,
Key Lookup과RID Lookup두가지가 있습니다 Key Lookup: Primary key가 존재하는 테이블에서 찾는 방식이며Clustered Index의Clustering Key를 이용하여 행의 위치를 탐색합니다RID Lookup: Primary key가 존재하지 않는 테이블에서 찾는 방식이며RID(데이터페이지변호, 슬롯번호, 파일번호)를 가지고HEAP에 저장된 실제 데이터를 찾습니다.
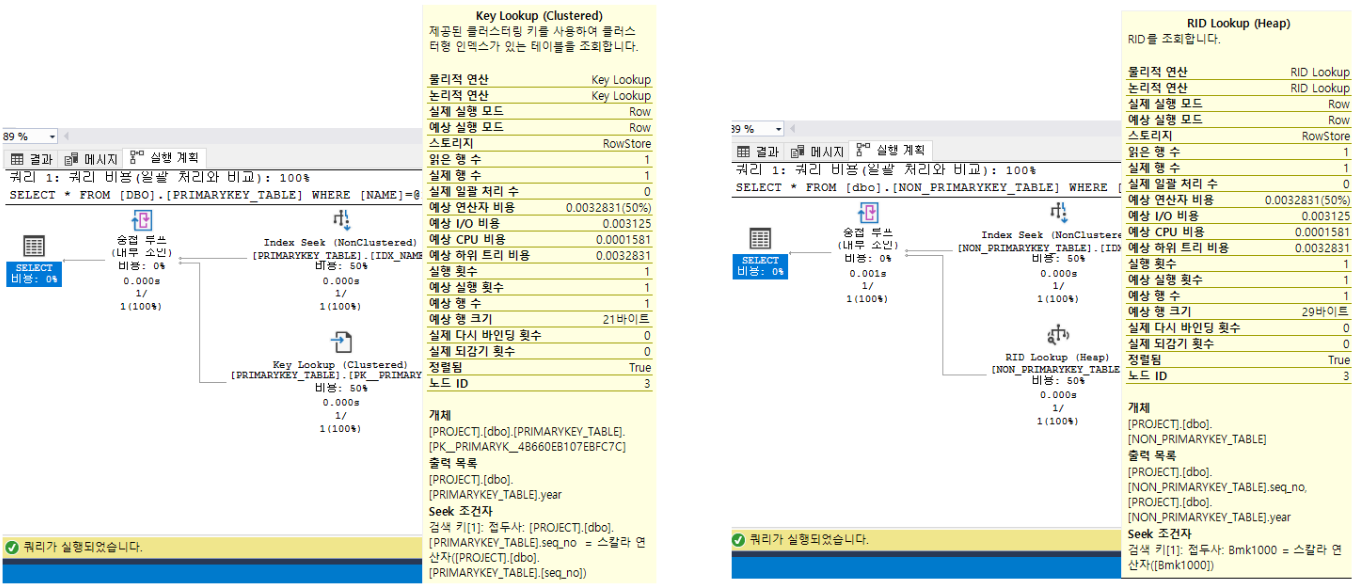
- MSSQL에서 인덱스 실행계획을 보면 인덱스 걸린 컬럼을 이용하여 탐색할 때 인덱스가 찾고자하는 행의 탐색방법이 나오는데,